Bulk functional analysis
Bulk RNA-seq yields many molecular readouts that are hard to interpret by themselves. One way of summarizing this information is by inferring pathway and transcription factor activities from prior knowledge.
In this notebook we showcase how to use decoupler for transcription factor (TF) and pathway activity inference from a human data-set. The data consists of 6 samples of hepatic stellate cells (HSC) where three of them were activated by the cytokine Transforming growth factor (TGF-β), it is available at GEO here.
Note
This tutorial assumes that you already know the basics of decoupler. Else, check out the Usage tutorial first.
Loading packages
First, we need to load the relevant packages, scanpy to handle RNA-seq data and decoupler to use statistical methods.
[1]:
import scanpy as sc
import decoupler as dc
# Only needed for processing
import numpy as np
import pandas as pd
from anndata import AnnData
Loading the data
We can download the data easily from GEO:
[2]:
!wget 'https://www.ncbi.nlm.nih.gov/geo/download/?acc=GSE151251&format=file&file=GSE151251%5FHSCs%5FCtrl%2Evs%2EHSCs%5FTGFb%2Ecounts%2Etsv%2Egz' -O counts.txt.gz
!gzip -d -f counts.txt.gz
--2023-02-13 11:26:57-- https://www.ncbi.nlm.nih.gov/geo/download/?acc=GSE151251&format=file&file=GSE151251%5FHSCs%5FCtrl%2Evs%2EHSCs%5FTGFb%2Ecounts%2Etsv%2Egz
Resolving www.ncbi.nlm.nih.gov (www.ncbi.nlm.nih.gov)... 130.14.29.110
Connecting to www.ncbi.nlm.nih.gov (www.ncbi.nlm.nih.gov)|130.14.29.110|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1578642 (1,5M) [application/octet-stream]
Saving to: ‘counts.txt.gz’
counts.txt.gz 100%[===================>] 1,50M 1,72MB/s in 0,9s
2023-02-13 11:26:58 (1,72 MB/s) - ‘counts.txt.gz’ saved [1578642/1578642]
We can then read it using pandas:
[3]:
# Read raw data and process it
adata = pd.read_csv('counts.txt', index_col=2, sep='\t').iloc[:, 5:].T
adata
[3]:
| GeneName | DDX11L1 | WASH7P | MIR6859-1 | MIR1302-11 | MIR1302-9 | FAM138A | OR4G4P | OR4G11P | OR4F5 | RP11-34P13.7 | ... | MT-ND4 | MT-TH | MT-TS2 | MT-TL2 | MT-ND5 | MT-ND6 | MT-TE | MT-CYB | MT-TT | MT-TP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 25_HSCs-Ctrl1 | 0 | 9 | 10 | 1 | 0 | 0 | 0 | 0 | 0 | 33 | ... | 93192 | 342 | 476 | 493 | 54466 | 17184 | 1302 | 54099 | 258 | 475 |
| 26_HSCs-Ctrl2 | 0 | 12 | 14 | 0 | 0 | 0 | 0 | 0 | 0 | 66 | ... | 114914 | 355 | 388 | 436 | 64698 | 21106 | 1492 | 62679 | 253 | 396 |
| 27_HSCs-Ctrl3 | 0 | 14 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 52 | ... | 155365 | 377 | 438 | 480 | 85650 | 31860 | 2033 | 89559 | 282 | 448 |
| 31_HSCs-TGFb1 | 0 | 11 | 16 | 0 | 0 | 0 | 0 | 0 | 0 | 54 | ... | 110866 | 373 | 441 | 481 | 60325 | 19496 | 1447 | 66283 | 172 | 341 |
| 32_HSCs-TGFb2 | 0 | 5 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 44 | ... | 45488 | 239 | 331 | 343 | 27442 | 9054 | 624 | 27535 | 96 | 216 |
| 33_HSCs-TGFb3 | 0 | 12 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 32 | ... | 70704 | 344 | 453 | 497 | 45443 | 13796 | 1077 | 43415 | 192 | 243 |
6 rows × 64253 columns
Note
In case your data does not contain gene symbols but rather gene ids like ENSMBL, you can use the function sc.queries.biomart_annotations to retrieve them. In this other vignette, ENSMBL ids are transformed into gene symbols.
Note
In case your data is not from human but rather a model organism, you can find their human orthologs using pypath. Check this GitHub issue where mouse genes are transformed into human.
The obtained data consist of raw read counts for six different samples (three controls, three treatments) for ~60k genes. Before continuing, we will transform our expression data into an AnnData object. It handles annotated data matrices efficiently in memory and on disk and is used in the scverse framework. You can read more about it here and here.
[4]:
# Transform to AnnData object
adata = AnnData(adata)
adata.var_names_make_unique()
adata
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
/Users/aureliendugourd/opt/anaconda3/lib/python3.8/site-packages/anndata/utils.py:111: UserWarning: Suffix used (-[0-9]+) to deduplicate index values may make index values difficult to interpret. There values with a similar suffixes in the index. Consider using a different delimiter by passing `join={delimiter}`Example key collisions generated by the make_index_unique algorithm: ['SNORD116-1', 'SNORD116-2', 'SNORD116-3', 'SNORD116-4', 'SNORD116-5']
[4]:
AnnData object with n_obs × n_vars = 6 × 64253
Inside an AnnData object, there is the .obs attribute where we can store the metadata of our samples. Here we will infer the metadata by processing the sample ids, but this could also be added from a separate dataframe:
[5]:
# Process treatment information
adata.obs['condition'] = ['control' if '-Ctrl' in sample_id else 'treatment' for sample_id in adata.obs.index]
# Process sample information
adata.obs['sample_id'] = [sample_id.split('_')[0] for sample_id in adata.obs.index]
# Visualize metadata
adata.obs
[5]:
| condition | sample_id | |
|---|---|---|
| 25_HSCs-Ctrl1 | control | 25 |
| 26_HSCs-Ctrl2 | control | 26 |
| 27_HSCs-Ctrl3 | control | 27 |
| 31_HSCs-TGFb1 | treatment | 31 |
| 32_HSCs-TGFb2 | treatment | 32 |
| 33_HSCs-TGFb3 | treatment | 33 |
Quality control
Before doing anything we need to ensure that our data passes some quality control thresholds. In transcriptomics it can happen that some genes were not properly profiled and thus need to be removed. We can check for lowly expressed genes by running this line:
[6]:
dc.plot_violins(adata, log=True, thr=4, title='Log-unnormalized counts per sample')
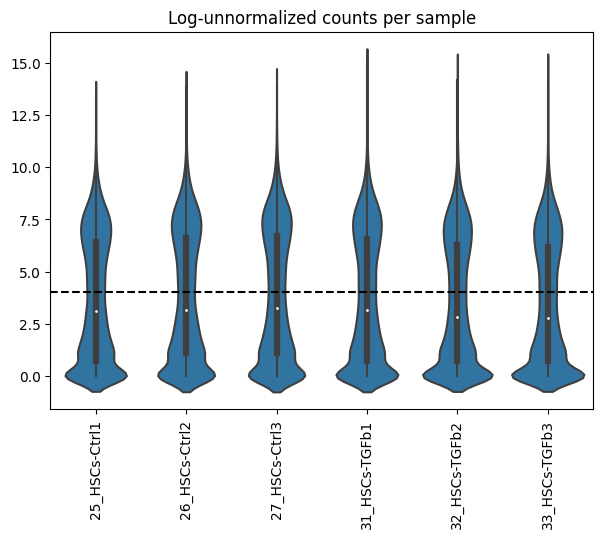
It can be observed that across samples there seems to be a bimodal distribution of lowly and highly expressed genes.
We can set the lowly expressed genes to 0, in this case less than 4:
[7]:
# Set features to 0
dc.mask_features(adata, log=True, thr=4)
Then we can remove samples with less than 200 highly expressed genes and genes that are not expressed across all samples.
Note
This thresholds can vary a lot between datasets, manual assessment of them needs to be considered. For example, it might be the case that many genes are not expressed in just one sample which they would get removed by the current setting. For this specific dataset it is fine.
[8]:
# Filter out samples
sc.pp.filter_cells(adata, min_genes=200)
# Filter out features not expressed in all samples (n=6)
sc.pp.filter_genes(adata, min_cells=adata.shape[0])
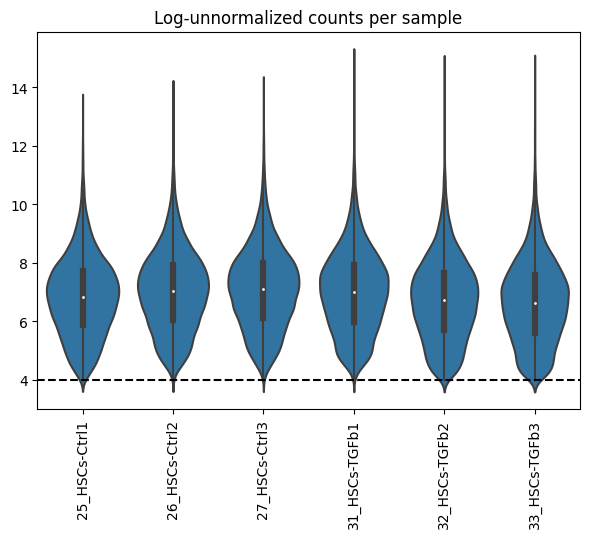
Now we can visualize again how the distributions look like after filtering:
[9]:
dc.plot_violins(adata, log=True, thr=4, title='Log-unnormalized counts per sample')
Normalization
In order to work with transcriptomics data we need to normalize it due to the high variance between readouts. Many normalization techniques exist but for simplicity, here we will use the log transformed Counts Per Million (CPM) normalization.
[10]:
# Log-CPM counts
sc.pp.normalize_total(adata, target_sum=1e6)
sc.pp.log1p(adata)
Now we visualize how the samples look like after normalization
[11]:
dc.plot_violins(adata, title='Log-CPM counts per sample')

Differential expression analysis
In order to identify which are the genes that are changing the most between treatment and control we can perform differential expression analysis (DEA). Like in normalization, many approaches exists but for simplicity here we use a t-test between groups.
[12]:
# Run DEA
logFCs, pvals = dc.get_contrast(adata,
group_col=None,
condition_col='condition',
condition='treatment',
reference='control',
method='t-test'
)
logFCs
[12]:
| CICP27 | MTND1P23 | MTND2P28 | AC114498.1 | MIR6723 | RP5-857K21.7 | MTATP8P1 | MTATP6P1 | RP5-857K21.11 | LINC01128 | ... | MT-ND4 | MT-TH | MT-TS2 | MT-TL2 | MT-ND5 | MT-ND6 | MT-TE | MT-CYB | MT-TT | MT-TP | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| treatment.vs.control | -0.135726 | -0.601098 | -0.450566 | -0.536081 | -0.870987 | -0.559755 | -0.841359 | -0.685194 | -0.650889 | 0.557 | ... | -0.718909 | -0.168917 | -0.075884 | -0.08817 | -0.64625 | -0.726885 | -0.649676 | -0.624246 | -0.809369 | -0.724974 |
1 rows × 14254 columns
After running DEA, we obtain how much each gene is changing in treatment compared to controls (logFCs), and how statistically singificant is this change (pvals).
We can further explore these changes by plotting them into a volcano plot.
[13]:
dc.plot_volcano(logFCs, pvals, 'treatment.vs.control', top=15, sign_thr=0.05, lFCs_thr=0.5)
/Users/aureliendugourd/opt/anaconda3/lib/python3.8/site-packages/pandas/plotting/_matplotlib/core.py:1114: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
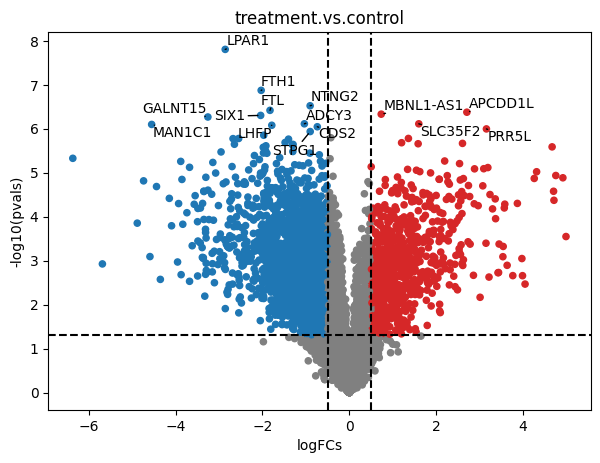
To extract the top significant genes after FDR correction (adj_pvals), we can run this:
[14]:
top_genes = dc.get_top_targets(logFCs, pvals, 'treatment.vs.control', sign_thr=0.05, lFCs_thr=0.5)
top_genes
[14]:
| contrast | name | logFCs | pvals | adj_pvals | |
|---|---|---|---|---|---|
| 0 | treatment.vs.control | LPAR1 | -2.856200 | 1.555664e-08 | 0.000222 |
| 1 | treatment.vs.control | FTH1 | -2.028517 | 1.330181e-07 | 0.000948 |
| 2 | treatment.vs.control | NTNG2 | -0.901692 | 2.986280e-07 | 0.000957 |
| 3 | treatment.vs.control | FTL | -1.825337 | 3.792117e-07 | 0.000957 |
| 4 | treatment.vs.control | APCDD1L | 2.706221 | 4.179862e-07 | 0.000957 |
| ... | ... | ... | ... | ... | ... |
| 3766 | treatment.vs.control | VAMP1 | -0.892178 | 2.064460e-02 | 0.049842 |
| 3767 | treatment.vs.control | RP11-214K3.25 | -0.652381 | 2.065199e-02 | 0.049852 |
| 3768 | treatment.vs.control | SLC26A6 | -0.787473 | 2.071529e-02 | 0.049964 |
| 3769 | treatment.vs.control | ANKDD1A | -1.015187 | 2.071600e-02 | 0.049964 |
| 3770 | treatment.vs.control | BCKDHB | -0.627068 | 2.072398e-02 | 0.049966 |
3771 rows × 5 columns
Pathway activity inference
To estimate pathway activities we will use the resource PROGENy and the consensus method.
For another example on pathway activities please visit this other notebook: Pathway activity inference.
[15]:
# Retrieve PROGENy model weights
progeny = dc.get_progeny(top=300)
# Infer pathway activities with consensus
pathway_acts, pathway_pvals = dc.run_consensus(mat=logFCs, net=progeny)
pathway_acts
[15]:
| Androgen | EGFR | Estrogen | Hypoxia | JAK-STAT | MAPK | NFkB | PI3K | TGFb | TNFa | Trail | VEGF | WNT | p53 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| treatment.vs.control | 0.073365 | 0.118365 | 0.193759 | 0.553584 | -1.43984 | 0.346702 | -0.46948 | 0.389558 | 2.78118 | -1.265739 | -0.077649 | 0.246556 | 0.080173 | -0.516283 |
After running the consensus method, we obtained activities and p-values for each pathway.
We can visualize by runnig this:
[16]:
dc.plot_barplot(pathway_acts, 'treatment.vs.control', top=25, vertical=False)
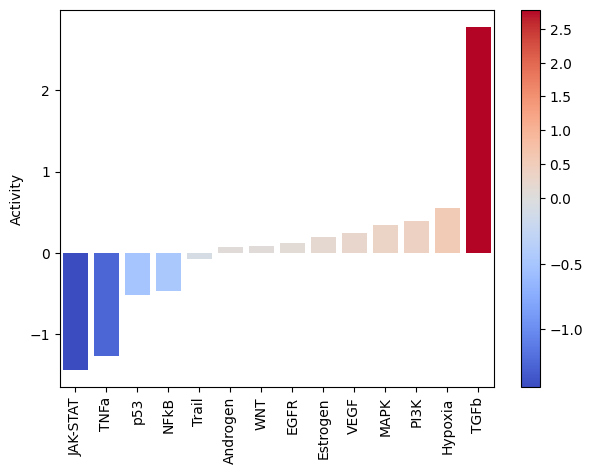
As expected, after treating cells with the cytokine TGFb we see an increase of activity for this pathway.
On the other hand, it seems that this treatment has decreased the activity of other pathways like JAK-STAT or TNFa.
We can visualize the targets of TFGb in a volcano plot:
[17]:
dc.plot_volcano(logFCs, pvals, 'treatment.vs.control', name='TGFb', net=progeny, top=5, sign_thr=0.05, lFCs_thr=0.5)
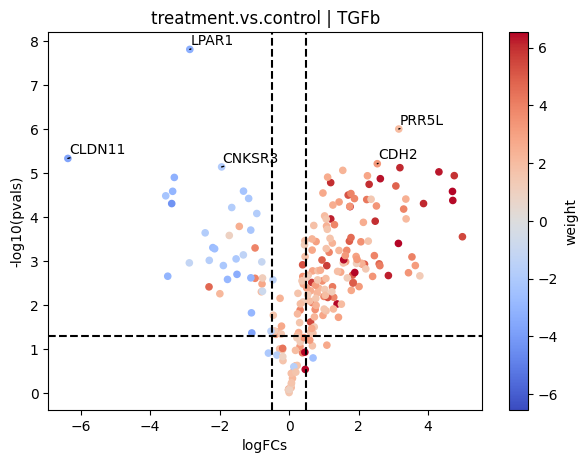
In this plot we can see that genes with positive weights towards TFGb have positive logFCs, while genes with negative weights have negative logFCs. This justifies the high activity that we observed.
On the contrary if we look at JAK-STAT:
[18]:
dc.plot_volcano(logFCs, pvals, 'treatment.vs.control', name='JAK-STAT', net=progeny, top=5, sign_thr=0.05, lFCs_thr=0.5)
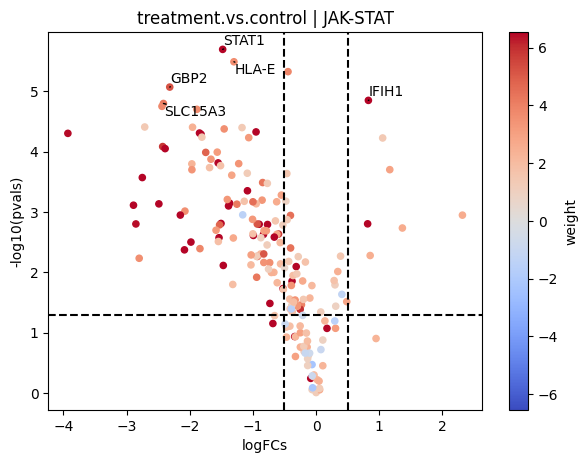
Here most of the downstream genes with positive weights of JAK-STAT seem to have negative logFCs, indicating that the pathway may be inactive compared to controls.
Transcription factor activity inference
Similarly to pathways, we can estimate transcription factor activities using the resource DoRothEA and the consensus method.
For another example on transcription factor activities please visit this other notebook: Transcription factor activity inference.
[19]:
# Retrieve DoRothEA gene regulatory network
dorothea = dc.get_dorothea()
# Infer pathway activities with consensus
tf_acts, tf_pvals = dc.run_consensus(mat=logFCs, net=dorothea)
tf_acts
[19]:
| AHR | AR | ARID2 | ARID3A | ARNT | ARNTL | ASCL1 | ATF1 | ATF2 | ATF3 | ... | ZNF217 | ZNF24 | ZNF263 | ZNF274 | ZNF384 | ZNF584 | ZNF592 | ZNF639 | ZNF644 | ZNF740 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| treatment.vs.control | -1.366343 | -0.223563 | 0.404413 | -0.129959 | -0.018752 | 0.49453 | -0.043476 | 0.283428 | 0.212838 | -0.244554 | ... | -0.610368 | -0.002194 | -1.472275 | -0.889195 | 0.754258 | -0.240207 | -0.039852 | 0.712267 | 0.65421 | 0.159675 |
1 rows × 278 columns
After running the consensus method, we obtained activities and p-values for each transcription factor.
We can visualize the most active and inactive transcription factor by runnig this:
[20]:
dc.plot_barplot(tf_acts, 'treatment.vs.control', top=25, vertical=True)
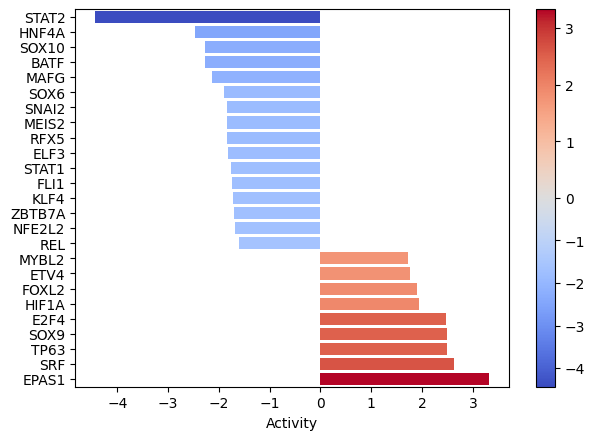
EPAS1, SRF, and TP63 seem to be the most activated in this treatment while STAT2, HNF4A AND SOX10 seem to be inactivated.
As before, we can manually inspect the downstream targets of each transcription factor:
[21]:
dc.plot_volcano(logFCs, pvals, 'treatment.vs.control', name='EPAS1', net=dorothea, top=5, sign_thr=0.05, lFCs_thr=0.5)
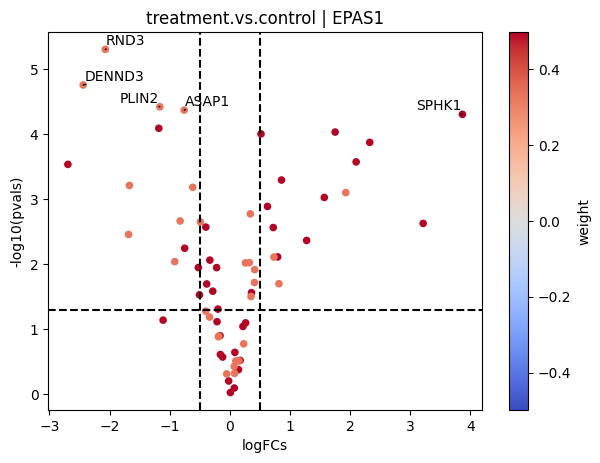
[22]:
dc.plot_volcano(logFCs, pvals, 'treatment.vs.control', name='STAT2', net=dorothea, top=5, sign_thr=0.05, lFCs_thr=0.5)
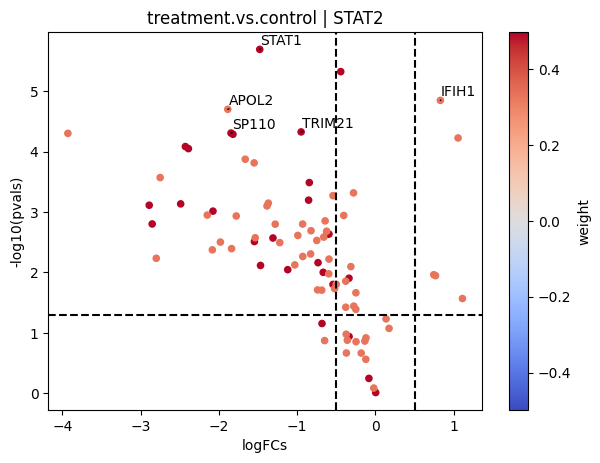
Functional enrichment of biological terms
We can also assign the obtained DEG biological terms using the resource MSigDB and the ora method.
For another example on functional enrichment of biological terms please visit this other notebook: Functional enrichment of biological terms.
[23]:
# Retrieve MSigDB resource
msigdb = dc.get_resource('MSigDB')
msigdb
# Filter by a desired geneset collection, for example hallmarks
msigdb = msigdb[msigdb['collection']=='hallmark']
msigdb = msigdb.drop_duplicates(['geneset', 'genesymbol'])
# Infer enrichment with ora using significant deg
top_genes = dc.get_top_targets(logFCs, pvals, 'treatment.vs.control', sign_thr=0.05, lFCs_thr=1.5)
enr_pvals = dc.get_ora_df(top_genes, msigdb, groupby='contrast', features='name', source='geneset', target='genesymbol')
enr_pvals
[23]:
| HALLMARK_ADIPOGENESIS | HALLMARK_ALLOGRAFT_REJECTION | HALLMARK_ANDROGEN_RESPONSE | HALLMARK_ANGIOGENESIS | HALLMARK_APICAL_JUNCTION | HALLMARK_APOPTOSIS | HALLMARK_COAGULATION | HALLMARK_COMPLEMENT | HALLMARK_EPITHELIAL_MESENCHYMAL_TRANSITION | HALLMARK_ESTROGEN_RESPONSE_EARLY | ... | HALLMARK_MITOTIC_SPINDLE | HALLMARK_MTORC1_SIGNALING | HALLMARK_MYOGENESIS | HALLMARK_P53_PATHWAY | HALLMARK_REACTIVE_OXYGEN_SPECIES_PATHWAY | HALLMARK_TGF_BETA_SIGNALING | HALLMARK_TNFA_SIGNALING_VIA_NFKB | HALLMARK_UV_RESPONSE_DN | HALLMARK_UV_RESPONSE_UP | HALLMARK_XENOBIOTIC_METABOLISM | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| treatment.vs.control | 5.764578e-11 | 7.876590e-17 | 7.876590e-17 | 4.889991e-08 | 1.373635e-28 | 1.373635e-28 | 3.564059e-24 | 1.205612e-25 | 0.0 | 4.072404e-27 | ... | 1.680132e-09 | 9.129221e-20 | 1.052105e-22 | 1.373635e-28 | 2.308692e-15 | 1.975060e-12 | 0.0 | 7.275542e-42 | 7.876590e-17 | 3.564059e-24 |
1 rows × 31 columns
We can then transform these p-values to their -log10 (so that the higher the value, the more significant the p-value). We will also set 0s to a minimum p-value so that we do not get infinites.
[24]:
# Set 0s to min p-value
enr_pvals.values[enr_pvals.values == 0] = np.min(enr_pvals.values[enr_pvals.values != 0])
# Log-transform
enr_pvals = -np.log10(enr_pvals)
Then we can visualize the most enriched terms:
[25]:
dc.plot_barplot(enr_pvals, 'treatment.vs.control', top=25, vertical=True)
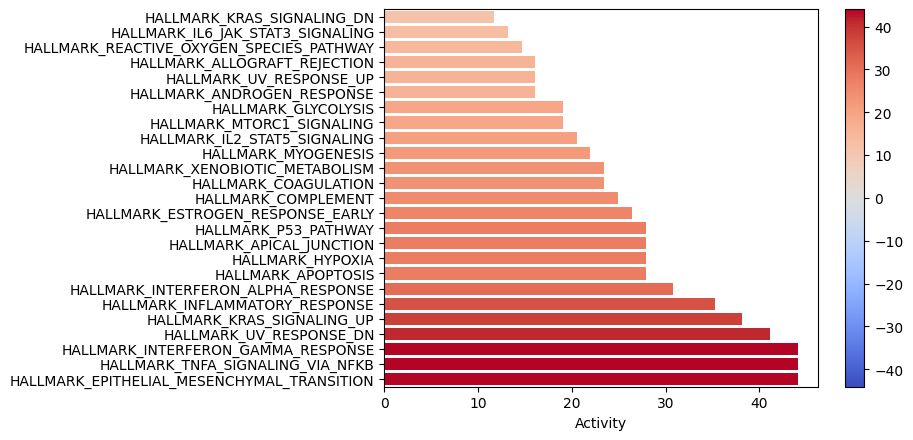
TNFa and interferons response (JAK-STAT) processes seem to be enriched. We previously observed a similar result with the PROGENy pathways, were they were significantly downregulated. Therefore, one of the limitations of using a prior knowledge resource without weights is that it doesn’t provide direction.
Enrichment of ligand-receptor interactions
Recently, study of interactions between ligands and receptors have gained significant traction, notably pushed by the democratization of single cell sequencing technologies. While most methods (such as the one described in LIANA) are developed for single cell datasets, they rely on a relatively simple assumption of co-expression or co-regulation of two (or more in the context of complexes) genes acting as ligand and receptors to propose hypothetical ligand-receptor interaction events. This concept can seamlessly be applied to a bulk RNA dataset, where the assumption is that sender and receiver cells are convoluted in a single dataset, but the observation of significant co-regulation of ligand and receptors should still correspond to hypothetical ligand-receptor interaction events.
At the core, most current ligand-receptor interaction methods rely on averaging the measurements obtained for ligand and receptor and standardizing them against a background distribution. Thus, an enrichment method based on a weighted mean can emulate this, where the sets are simply the members of a ligand receptor pair (or more in the context of complexes).
Thus, we can extract ligand-receptor interaction ressources from the LIANA package (available both in R and python), and use it as a prior knowledge network with decoupler to find the most significant pairs of ligand-receptors in a given bulk dataset.
While more work is required to fully understand the functional relevance of the highlighted ligand-receptor interactions with such an approach, this represents a very straightforward and intuitive approach to embed a bulk RNA dataset with ligand-receptor interaction prior knowledge.
First, we extract ligand-receptor interactions from liana, and decomplexify them to format them into an appropriate decoupleR input.
[26]:
import liana as ln
liana_lr = ln.resource.select_resource()
liana_lr = ln.resource.explode_complexes(liana_lr)
# Create two new DataFrames, each containing one of the pairs of columns to be concatenated
df1 = liana_lr[['interaction', 'ligand']]
df2 = liana_lr[['interaction', 'receptor']]
# Rename the columns in each new DataFrame
df1.columns = ['interaction', 'genes']
df2.columns = ['interaction', 'genes']
# Concatenate the two new DataFrames
liana_lr = pd.concat([df1, df2], axis=0)
liana_lr['weight'] = 1
# Find duplicated rows
duplicates = liana_lr.duplicated()
# Remove duplicated rows
liana_lr = liana_lr[~duplicates]
liana_lr
[26]:
| interaction | genes | weight | |
|---|---|---|---|
| 0 | LGALS9|PTPRC | LGALS9 | 1 |
| 1 | LGALS9|MET | LGALS9 | 1 |
| 2 | LGALS9|CD44 | LGALS9 | 1 |
| 3 | LGALS9|LRP1 | LGALS9 | 1 |
| 4 | LGALS9|CD47 | LGALS9 | 1 |
| ... | ... | ... | ... |
| 5849 | BMP2|ACTR2 | ACTR2 | 1 |
| 5850 | BMP15|ACTR2 | ACTR2 | 1 |
| 5851 | CSF1|CSF3R | CSF3R | 1 |
| 5852 | IL36G|IFNAR1 | IFNAR1 | 1 |
| 5853 | IL36G|IFNAR2 | IFNAR2 | 1 |
10532 rows × 3 columns
Then we can use the weighted mean to find the significant co-regulated pairs of ligand and receptors.
[27]:
# Infer pathway activities with consensus
lr_mean, lr_norm_mean, lr_corr_mean, lr_pvalue = dc.run_wmean(mat=logFCs, net=liana_lr, source='interaction', target='genes', min_n=2, times = 100)
[28]:
dc.plot_barplot(lr_norm_mean, 'treatment.vs.control', top=25, vertical=True)
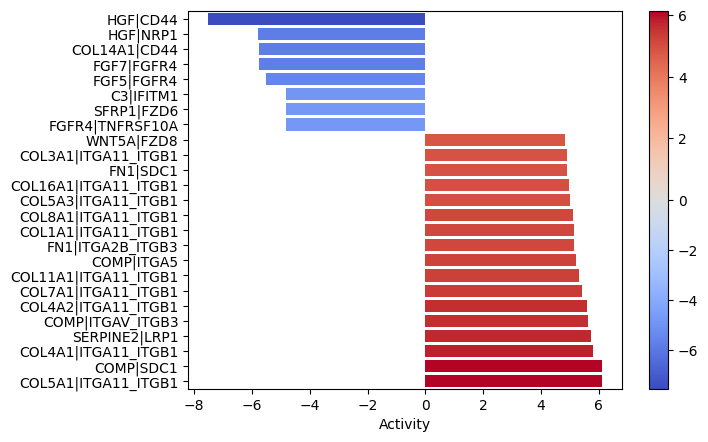
Interactions between colagens/FN1 and the ITGA11_ITGB1 complexe seems to be quite enrichned with up-regulated logFCs. That is especially relevant since the EMT pathway was significantly enriched in the functional pathway analysis.