Pseudo-bulk functional analysis
When cell lineage is clear (there are clear cell identity clusters), it might be beneficial to perform functional analyses at the pseudo-bulk level instead of the single-cell. By doing so, we recover lowly expressed genes that before where affected by the “drop-out” effect of single-cell. Additionaly, if there is more than one condition in our data, we can perform differential expression analysis (DEA) and use the gene statistics as input for bioactivity inference.
In this notebook we showcase how to use decoupler for transcription factor (TF) and pathway activity inference from a human data-set. The data consists of ~5k Blood myeloid cells from healthy and COVID-19 infected patients available in the Single Cell Expression Atlas here.
Note
This tutorial assumes that you already know the basics of decoupler. Else, check out the Usage tutorial first.
Loading packages
First, we need to load the relevant packages, scanpy to handle scRNA-seq data and decoupler to use statistical methods.
[1]:
import scanpy as sc
import decoupler as dc
# Only needed for processing and plotting
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
Loading the data
We can download the data easily using scanpy:
[2]:
# Download data-set
adata = sc.datasets.ebi_expression_atlas("E-MTAB-9221", filter_boring=True)
# Rename meta-data
columns = ['Sample Characteristic[sex]',
'Sample Characteristic[individual]',
'Sample Characteristic[disease]',
'Factor Value[inferred cell type - ontology labels]']
adata.obs = adata.obs[columns]
adata.obs.columns = ['sex','individual','disease','cell_type']
adata
[2]:
AnnData object with n_obs × n_vars = 6178 × 18958
obs: 'sex', 'individual', 'disease', 'cell_type'
Processing
This specific data-set contains ensmbl gene ids instead of gene symbols. To be able to use decoupler we need to transform them into gene symbols:
[3]:
# Retrieve gene symbols
annot = sc.queries.biomart_annotations("hsapiens",
["ensembl_gene_id", "external_gene_name"],
).set_index("ensembl_gene_id")
# Filter genes not in annotation
adata = adata[:, adata.var.index.intersection(annot.index)]
# Assign gene symbols
adata.var['gene_symbol'] = [annot.loc[ensembl_id,'external_gene_name'] for ensembl_id in adata.var.index]
adata.var = adata.var.reset_index().rename(columns={'index': 'ensembl_gene_id'}).set_index('gene_symbol')
# Remove genes with no gene symbol
adata = adata[:, ~pd.isnull(adata.var.index)]
# Remove duplicates
adata.var_names_make_unique()
Trying to set attribute `.var` of view, copying.
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Since the meta-data of this data-set is available, we can filter cells that were not annotated:
[4]:
# Remove non-annotated cells
adata = adata[~adata.obs['cell_type'].isnull()]
We will store the raw counts in the .layers attribute so that we can use them afterwards to generate pseudo-bulk profiles.
[5]:
# Store raw counts in layers
adata.layers['counts'] = adata.X
# Normalize and log-transform
sc.pp.normalize_total(adata, target_sum=1e4)
sc.pp.log1p(adata)
adata.layers['normalized'] = adata.X
We can also look how cells cluster by cell identity:
[6]:
# Identify highly variable genes
sc.pp.highly_variable_genes(adata, batch_key='individual')
# Scale the data
sc.pp.scale(adata, max_value=10)
# Generate PCA features
sc.tl.pca(adata, svd_solver='arpack', use_highly_variable=True)
# Compute distances in the PCA space, and find cell neighbors
sc.pp.neighbors(adata)
# Generate UMAP features
sc.tl.umap(adata)
# Visualize
sc.pl.umap(adata, color=['disease','cell_type'], frameon=False)
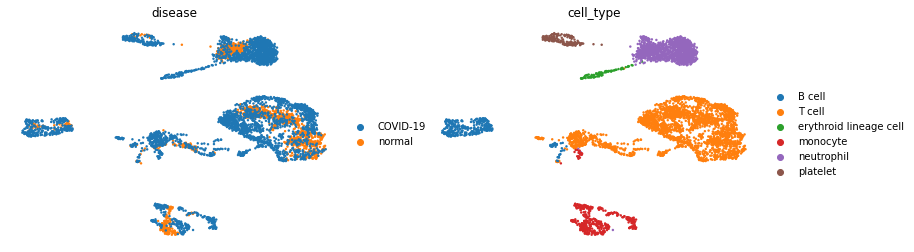
In this data-set we have two condition, COVID-19 and healthy, across 6 different cell types.
Generation of pseudo-bulk profiles
After the annotation of clusters into cell indentities, we often would like to perform differential expression analysis (DEA) between conditions within particular cell types to further characterise them. DEA can be performed at the single-cell level, but the obtained p-values are often inflated as each cell is treated as a sample. We know that single cells within a sample are not independent of each other, since they were isolated from the same enviroment. If we treat cells as samples, we are not testing the variation across a population of samples, rather the variation inside an individual one. Moreover, if a sample has more cells than another it might bias the results.
The current best practice to correct for this is using a pseudo-bulk approach, which involves the following steps:
Subsetting the cell type(s) of interest to perform DEA.
Extracting their raw integer counts.
Summing their counts per gene into a single profile if they pass quality control.
Normalize aggregated counts.
Performing DEA if at least two biological replicates per condition are available (more replicates are recommended).
A crucial step of pseudo-bulking is filtering out genes that are not expressed across most cells and samples, since they are very noisy and can result in unstable log fold changes. decoupler has a helper function that performs pseudo-bulking. To get robust profiles, genes are filtered out if they are not expressed in an enough proportion of cells per sample (min_prop) and if this requirement is not true across enough samples (min_smpls).
[7]:
# Get pseudo-bulk profile
padata = dc.get_pseudobulk(adata, sample_col='individual', groups_col='cell_type', layer='counts', min_prop=0.2, min_smpls=3)
# Normalize
sc.pp.normalize_total(padata, target_sum=1e4)
sc.pp.log1p(padata)
padata
/home/badi/miniconda3/envs/decoupler/lib/python3.8/site-packages/scanpy/preprocessing/_normalization.py:155: UserWarning: Revieved a view of an AnnData. Making a copy.
view_to_actual(adata)
[7]:
AnnData object with n_obs × n_vars = 26 × 6480
obs: 'sex', 'individual', 'disease', 'cell_type'
uns: 'log1p'
Contrast between conditions
Once we have generated robust pseudo-bulk profiles for each sample and cell type, we can run any statistical test to compute DEA. For this exaple we will use t-test as is implemented in scanpy but we could use any other.
[8]:
logFCs, pvals = dc.get_contrast(padata,
group_col='cell_type',
condition_col='disease',
condition='COVID-19',
reference='normal',
method='t-test'
)
logFCs
[8]:
| DPM1 | FGR | FUCA2 | GCLC | STPG1 | ANKIB1 | CYP51A1 | KRIT1 | BAD | LAP3 | ... | MATR3-1 | FRG1CP | GTF2IP12 | SCO2 | CCDC39 | TBCE-1 | POLR2J3-1 | MKKS-1 | DERPC | NOTCH2NLC | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B cell | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -0.293524 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.278328 | 0.000000 | 0.000000 | 0.000000 | -0.277882 | -0.332378 | 0.153742 | 0.000000 | 0.000000 | -0.485110 |
| T cell | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -0.612286 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | -0.044649 | -0.059458 | 0.000000 | 0.000000 | -0.332031 | 0.069898 | 0.156073 | 0.000000 | 0.000000 | -0.327738 |
| monocyte | 0.037755 | -0.323946 | 0.255671 | -0.474359 | -0.580443 | 0.182771 | 0.613953 | -0.280198 | 0.218523 | -0.150354 | ... | 0.110682 | 0.584123 | -0.002714 | 0.008861 | 0.155721 | 0.059474 | 0.357532 | -0.302924 | 0.005063 | -0.462076 |
| neutrophil | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -0.346927 | 0.000000 | 0.000000 | 0.000000 |
4 rows × 6480 columns
For each cell type, we will obtain a log fold change (logFC) between conditions and their associated p-value (pvals). These can be used to estimate biological activities such as TF or pathway activities.
Pathway activity inference
To estimate pathway activities we will use the resource PROGENy and the method mlm. For another example on pathway activities please visit this other notebook: Pathway activity inference.
[9]:
# Retrieve PROGENy model weights
progeny = dc.get_progeny(top=300)
# Infer pathway activities with mlm
pathway_acts, pathway_pvals = dc.run_mlm(mat=logFCs, net=progeny, source='source', target='target', weight='weight')
pathway_acts
[9]:
| Androgen | EGFR | Estrogen | Hypoxia | JAK-STAT | MAPK | NFkB | PI3K | TGFb | TNFa | Trail | VEGF | WNT | p53 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B cell | -0.397029 | 2.480973 | 0.242809 | -0.470050 | 1.174805 | -0.592690 | 0.657556 | 0.086395 | -1.823296 | -0.702840 | 0.317699 | -0.287403 | -0.352241 | 0.162409 |
| T cell | 1.311220 | 1.237633 | 0.548798 | -0.496405 | 2.381903 | -1.994873 | -3.854623 | 0.384836 | -3.187883 | 0.417350 | 0.276693 | -1.436762 | 1.788910 | -0.160297 |
| monocyte | -0.103896 | 0.642392 | 0.217333 | -0.011800 | 3.237967 | -0.570627 | -2.343546 | 1.561975 | -0.969763 | 0.114707 | 0.669750 | -1.138162 | -0.774484 | 0.073419 |
| neutrophil | 1.489143 | 1.494013 | -0.503044 | 1.607968 | -0.224128 | -2.327707 | -3.928730 | -1.989469 | -1.027945 | 0.827057 | 4.829114 | -1.304940 | 0.329553 | -0.992320 |
Let us plot the obtained scores:
[10]:
sns.clustermap(pathway_acts, center=0, cmap='coolwarm')
plt.show()
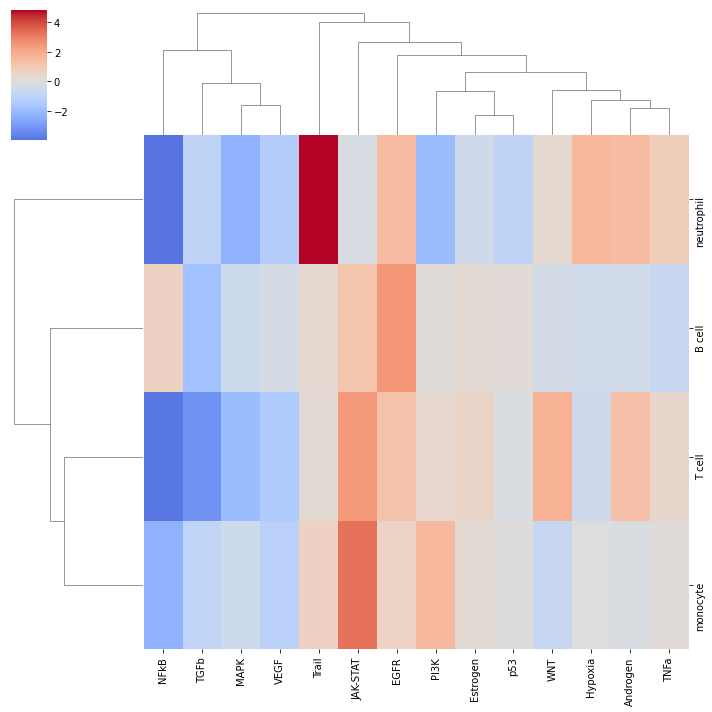
It looks like JAK-STAT is active across cell types in COVID-19. To further explore how the target genes behave, we can plot them in a volcano plot:
[11]:
dc.plot_volcano(logFCs, pvals, 'JAK-STAT', 'monocyte', progeny, top=5, source='source', target='target', weight='weight', sign_thr=0.05, lFCs_thr=0.5)
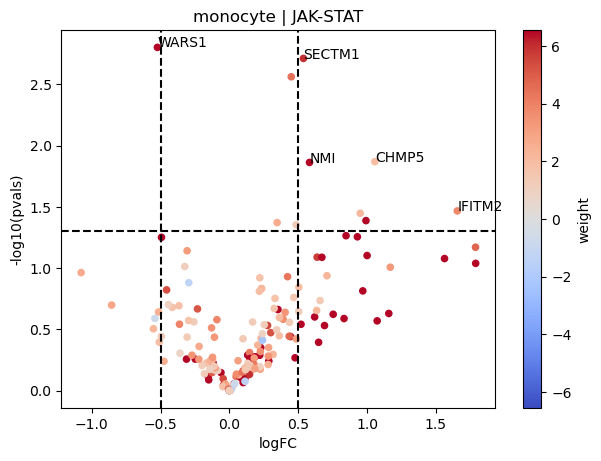
As an example, we can see that most genes that belong to the JAK-STAT pathway appear to be upregulated in COVID-19 monocytes compared to normal patients.
[12]:
dc.plot_volcano(logFCs, pvals, 'NFkB', 'T cell', progeny, top=5, source='source', target='target', weight='weight', sign_thr=0.05, lFCs_thr=0.5)
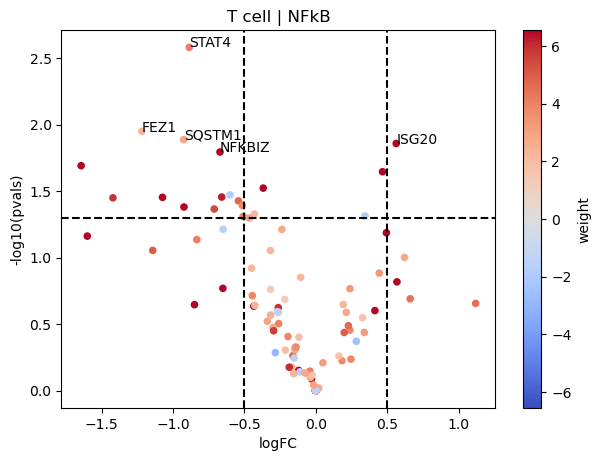
On the other hand, NFkB seems to be downregulated in T cells since most of its target genes are downregulated in COVID-19 samples.
Transcription factor activity inference
Similarly to pathways, we can estimate transcription factor activities using the resource DoRothEA and the method mlm. For another example on transcription factor activities please visit this other notebook: Transcription factor activity inference.
[13]:
# Retrieve DoRothEA gene regulatory network
dorothea = dc.get_dorothea()
# Infer pathway activities with mlm
tf_acts, tf_pvals = dc.run_mlm(mat=logFCs, net=dorothea, source='source', target='target', weight='weight')
tf_acts
[13]:
| AHR | AR | ARID2 | ARID3A | ARNT | ASCL1 | ATF1 | ATF2 | ATF3 | ATF4 | ... | ZHX2 | ZKSCAN1 | ZNF143 | ZNF217 | ZNF263 | ZNF274 | ZNF384 | ZNF592 | ZNF639 | ZNF740 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B cell | -0.334011 | -2.042455 | 0.579896 | -0.237316 | -0.029231 | -0.891553 | 1.005446 | -1.475539 | 1.109695 | 0.265752 | ... | -0.685154 | -0.238333 | -1.045387 | -0.233983 | 1.366188 | 0.739525 | -0.078644 | -1.591425 | -0.588697 | -0.222175 |
| T cell | -0.964815 | 0.928663 | -1.521186 | -0.772404 | 0.633283 | 0.018317 | -0.923358 | -3.826917 | 1.248572 | -1.629901 | ... | -1.126328 | -0.462567 | 0.669651 | -0.582991 | -0.406874 | 1.637458 | -0.921419 | -0.953223 | 0.154487 | 0.274283 |
| monocyte | 0.386445 | -1.305954 | 0.166629 | -0.729245 | -0.321365 | -0.868416 | 1.151295 | -1.918107 | 1.444672 | -1.529401 | ... | 0.204390 | -0.344114 | -1.293774 | 0.599333 | -0.272292 | 1.109508 | 0.035943 | -0.053248 | -0.009836 | -0.453317 |
| neutrophil | 0.926223 | 1.203207 | 0.462861 | -1.537997 | -0.638720 | -1.778534 | 1.464993 | -0.687862 | 1.450281 | 1.462705 | ... | 0.855751 | 0.356616 | -1.333536 | 1.172707 | 0.189980 | 0.289500 | -0.216159 | -0.068772 | -0.178796 | -0.524104 |
4 rows × 238 columns
Let us plot the obtained scores for the top active/inactive transcription factors:
[14]:
# Get top 5 most active/inactive sources
top = 5
top_idxs = set()
for row in tf_acts.values:
sort_idxs = np.argsort(-np.abs(row))
top_idxs.update(sort_idxs[:top])
top_idxs = np.array(list(top_idxs))
top_names = tf_acts.columns[top_idxs]
names = tf_acts.index.values
top = pd.DataFrame(tf_acts.values[:,top_idxs], columns=top_names, index=names)
# Plot
sns.clustermap(top, center=0, cmap='coolwarm')
plt.show()
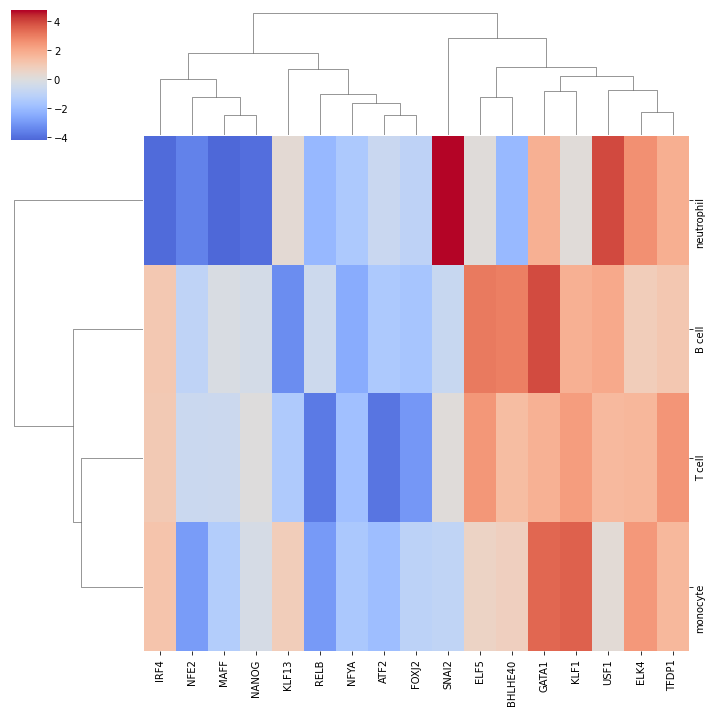
Like with pathways, we can explore how the target genes look like:
[15]:
dc.plot_volcano(logFCs, pvals, 'ELF5', 'B cell', dorothea, top=5, source='source', target='target', weight='weight', sign_thr=0.05, lFCs_thr=0.5)
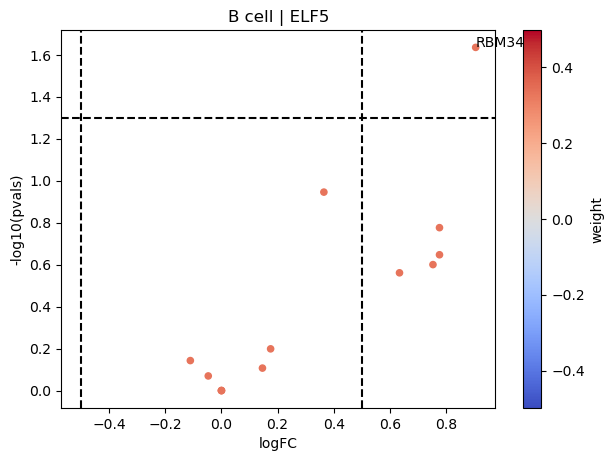
For example, ELF5 seems to be active in B cells since their positive targets are up-regulated in COVID-19.
[16]:
dc.plot_volcano(logFCs, pvals, 'RELB', 'T cell', dorothea, top=5, source='source', target='target', weight='weight', sign_thr=0.05, lFCs_thr=0.5)
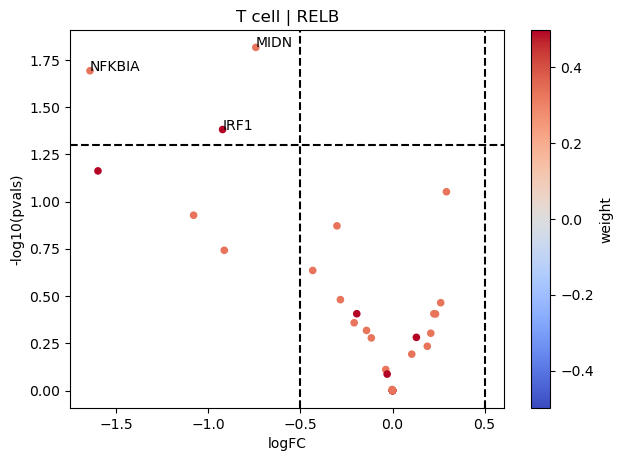
On the other hand, RELB seems to be inactive in T cells since their positive targets are down-regulated in COVID-19.